Imagine your core production services are experiencing a sudden, massive traffic spike. Pods are scaling rapidly, but suddenly, the scaling halts. Your pods sit in a dreaded Pending state for five to ten minutes while your cloud provider slowly provisions virtual machines. In the high-stakes world of modern cloud engineering, this delay can destroy your SLOs, trigger cascading failures, and cost thousands of dollars in lost revenue. Choosing the right tool for the job—specifically, evaluating karpenter vs cluster autoscaler—is the difference between a resilient, self-healing system and an operational nightmare. In this comprehensive 2026 guide, we will break down the architectural differences, performance metrics, and migration strategies to help you choose the ultimate scaling engine for your infrastructure.
- Why Node Autoscaling is a Hard Engineering Problem
- Cluster Autoscaler: Architecture, Mechanics, and Limitations
- Karpenter: The Groupless Evolution and How It Works
- Karpenter vs Cluster Autoscaler: 12-Point Comparison
- Deep-Dive Performance and Cost Benchmarks
- Multi-Cloud Realities: AWS, Azure, and Karpenter GCP 2026
- On-Premises Kubernetes: Is Autoscaling Ever Worth It?
- Step-by-Step Karpenter AWS Tutorial and Migration Path
- Kubernetes Node Autoscaling Best Practices
- Key Takeaways: The 2026 Decision Matrix
- Frequently Asked Questions
- Conclusion
Why Node Autoscaling is a Hard Engineering Problem
At its core, node autoscaling is a classic optimization problem with conflicting constraints. On one hand, you want compute resources to be immediately available the millisecond a workload demands them. On the other hand, you want to minimize idle capacity to avoid burning your cloud budget on unused virtual machines.
In a static infrastructure model, teams typically default to one of two suboptimal strategies:
- Over-provisioning: You run enough nodes to handle peak load at all times. Your average utilization sits at a wasteful 20–30%, and you pay for the other 70–80% to sit completely idle.
- Under-provisioning: You run lean, but when traffic spikes, pods go into a
Pendingstate. Your Service Level Objectives (SLOs) breach, your application latency skyrockets, and your on-call engineers get paged at 3:00 AM to manually add capacity.
When you introduce dynamic horizontal pod autoscaling (HPA), the problem shifts. The HPA can spin up dozens of new pod replicas in milliseconds, but the underlying infrastructure cannot keep pace. This creates the "thundering herd at scale-up" pattern: the application layer demands immediate capacity, but the infrastructure layer takes minutes to respond.
To bridge this gap, a kubernetes autoscaler comparison must examine not just how fast a tool can launch a node, but how intelligently it can select, bin-pack, and consolidate those nodes under dynamic real-world conditions.
Cluster Autoscaler: Architecture, Mechanics, and Limitations
Cluster Autoscaler (CA) is a highly mature, SIG-autoscaling project that has been the industry standard since 2016. It is battle-tested, supports a massive list of cloud providers, and follows a conservative, highly predictable operational model.
The Node Group Model
CA does not manage individual virtual machines directly. Instead, it delegates that responsibility to cloud provider abstractions, such as AWS Auto Scaling Groups (ASGs), Google Cloud Managed Instance Groups (MIGs), or Azure Virtual Machine Scale Sets (VMSS).
[Pending Pods] ──> [Cluster Autoscaler] ──> [Cloud API: Resize ASG/MIG] ──> [New VM Boots]
When a pod cannot be scheduled due to resource constraints, CA performs a loop (typically every 10 seconds) to simulate whether adding a node to an existing node group would resolve the scheduling failure. If a match is found, CA calls the cloud provider's API to increase the "desired capacity" of that specific node group. The cloud provider then provisions the VM, bootstraps the kubelet, and joins the node to the cluster.
To control which node group scales up when multiple groups match, CA uses expanders. Common expanders include: - least-waste: Chooses the node group that will have the least idle CPU/memory after scheduling the pending pods. - most-pods: Selects the group that can schedule the maximum number of pending pods. - priority: Allows operators to define a custom ordering of node groups via a ConfigMap. - random: A simple fallback option with no optimization logic.
Production-Ready Cluster Autoscaler Configuration
Below is a production-tuned manifest for Cluster Autoscaler on AWS, implementing resource limits, discovery tags, and aggressive scale-down parameters:
yaml apiVersion: apps/v1 kind: Deployment metadata: name: cluster-autoscaler namespace: kube-system spec: replicas: 1 selector: matchLabels: app: cluster-autoscaler template: metadata: labels: app: cluster-autoscaler annotations: cluster-autoscaler.kubernetes.io/safe-to-evict: "false" spec: priorityClassName: system-cluster-critical serviceAccountName: cluster-autoscaler containers: - image: registry.k8s.io/autoscaling/cluster-autoscaler:v1.30.3 name: cluster-autoscaler resources: requests: cpu: 100m memory: 600Mi limits: cpu: 200m memory: 1Gi command: - ./cluster-autoscaler - --cloud-provider=aws - --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/my-cluster - --expander=least-waste - --balance-similar-node-groups=true - --scale-down-delay-after-add=10m - --scale-down-unneeded-time=10m - --scale-down-utilization-threshold=0.5 - --max-graceful-termination-sec=600 - --scan-interval=10s
Key Limitations of Cluster Autoscaler
While highly reliable, Cluster Autoscaler suffers from architectural bottlenecks that limit its efficiency in modern, fast-paced environments:
- Node Group Lock-in: Because CA relies on pre-configured templates, every node in a group must be identical. If you have diverse workloads (e.g., GPU-heavy, memory-heavy, and cheap spot-instance tasks), you must pre-configure and manage dozens of distinct node groups.
- No Right-Sizing: CA cannot dynamically provision a custom instance size based on a pod's exact requirements. If a pod requests 12 vCPUs and your only matching node group is configured for
m5.large(2 vCPUs) orm5.16xlarge(64 vCPUs), CA will either fail to schedule or provision a massive, highly wasteful instance. - Slow Feedback Loops: The multi-step process of polling pending pods, simulating templates, resizing the ASG, and waiting for the cloud provider's VM initialization adds significant latency. It is common for CA scale-ups to take 5 to 10 minutes from the initial pending state to a running pod.
Karpenter: The Groupless Evolution and How It Works
Karpenter, originally developed by AWS and now a CNCF incubating project, represents a paradigm shift in Kubernetes cluster autoscaling. Instead of working within the constraints of cloud-native node groups, Karpenter bypasses them entirely, interacting directly with cloud provider APIs to provision individual, right-sized virtual machines on demand.
[Pending Pods] ──> [Karpenter (Event-Driven)] ──> [Direct EC2 RunInstances API] ──> [Node Joins in 60s]
Bypassing the Node Group
Karpenter operates on a groupless model. It does not look at ASGs, MIGs, or VMSSs. When a pod enters a Pending state, Karpenter's event-driven controller instantly evaluates the pod's specific requirements: CPU/memory requests, node selectors, tolerations, topology spread constraints, and affinities.
Karpenter then queries the cloud provider's real-time catalog of available instance types, prices, and zones. It dynamically calculates the most cost-effective instance type (or set of types) that can satisfy the pending pods, and calls the cloud API (e.g., EC2 RunInstances) directly. The new node joins the cluster as an independent entity, managed directly by Karpenter via Kubernetes NodeClaim custom resources.
Declarative Configuration: NodePool and EC2NodeClass
In Karpenter v1 (which stabilized in late 2024 and is the standard in 2026), configuration is split into two primary Custom Resource Definitions (CRDs):
- EC2NodeClass: Defines the cloud-specific infrastructure parameters (subnets, security groups, AMIs, block device mappings, and IAM roles).
- NodePool: Defines the scheduling constraints, instance family requirements, capacity types (Spot vs. On-Demand), and disruption/consolidation policies.
Here is a production-grade Karpenter v1 configuration matching modern standards:
yaml apiVersion: karpenter.k8s.aws/v1 kind: EC2NodeClass metadata: name: default spec: amiSelectorTerms: - alias: al2023@latest role: "KarpenterNodeRole-my-cluster" subnetSelectorTerms: - tags: karpenter.sh/discovery: "my-cluster" securityGroupSelectorTerms: - tags: karpenter.sh/discovery: "my-cluster" blockDeviceMappings: - deviceName: /dev/xvda ebs: volumeSize: 50Gi volumeType: gp3 encrypted: true metadataOptions: httpTokens: required httpPutResponseHopLimit: 1
apiVersion: karpenter.sh/v1 kind: NodePool metadata: name: general-purpose spec: template: spec: nodeClassRef: group: karpenter.k8s.aws kind: EC2NodeClass name: default requirements: - key: karpenter.sh/capacity-type operator: In values: ["on-demand", "spot"] - key: kubernetes.io/arch operator: In values: ["amd64", "arm64"] - key: karpenter.k8s.aws/instance-category operator: In values: ["c", "m", "r"] - key: karpenter.k8s.aws/instance-generation operator: Gt values: ["5"] - key: karpenter.k8s.aws/instance-size operator: NotIn values: ["nano", "micro", "small", "medium", "large"] expireAfter: 720h limits: cpu: "1000" memory: 1000Gi disruption: consolidationPolicy: WhenEmptyOrUnderutilized consolidateAfter: 5m budgets: - nodes: "5%" schedule: "0 8 * * mon-fri" duration: 10h
Advanced Consolidation and Drift Detection
Karpenter's primary competitive advantage is its active consolidation engine. It continuously monitors the cluster's active nodes (every 10 seconds) to identify optimization opportunities.
If Karpenter detects that a node is underutilized, it will evaluate whether the running pods can be rescheduled onto other existing nodes (Delete Consolidation). Even more impressively, if a workload running on an expensive c5.4xlarge instance has scaled down and now only requires 2 vCPUs, Karpenter will automatically provision a cheaper c5.xlarge instance, migrate the pods, and terminate the larger instance (Replace Consolidation).
Additionally, Karpenter features native Drift Detection. If you update your EC2NodeClass with a new AMI or security group, Karpenter flags all existing nodes provisioned under the old configuration as "drifted." It then orchestrates a graceful rolling upgrade, replacing the drifted nodes with new ones that match the updated specification, completely eliminating the need for complex, manual node-drain scripts.
Karpenter vs Cluster Autoscaler: 12-Point Comparison
To help you evaluate these tools, let’s compare them across 12 critical operational dimensions:
| Dimension | Karpenter | Cluster Autoscaler |
|---|---|---|
| 1. Node Provisioning Model | Groupless (direct cloud API calls) | Node Group-based (ASG, MIG, VMSS) |
| 2. Provisioning Speed | 60–90 seconds (near-instantaneous) | 5–10 minutes (highly reactive) |
| 3. Instance Selection | Dynamic (any matching type in the cloud catalog) | Static (predefined node group configurations) |
| 4. Multi-Dimensional Bin-Packing | Advanced (calculates optimal size at runtime) | Basic (first-fit heuristics based on templates) |
| 5. Node Consolidation | Continuous (replaces and down-sizes active nodes) | Scale-down only (removes completely empty nodes) |
| 6. Spot Instance Handling | Native (diversifies types, auto-falls back to on-demand) | Limited (one type per group, manual fallback) |
| 7. Drift Detection & Remediation | Built-in (automatically rolls nodes on config changes) | None (requires external tooling or manual drains) |
| 8. Configuration Complexity | Moderate (requires CRDs: NodePool & EC2NodeClass) | Low (configured via Helm chart values/CLI flags) |
| 9. Cloud Provider Support | AWS (stable), Azure (stable), GCP (beta) | AWS, GCP, Azure, DigitalOcean, and 10+ others |
| 10. On-Premises / Bare Metal Support | No (requires direct cloud API integrations) | Yes (via Cluster API / on-prem provider drivers) |
| 11. GPU / Accelerator Awareness | Native (selects correct GPU model based on requests) | Requires dedicated, pre-configured GPU node groups |
| 12. Project Maturity | CNCF Incubating (v1.0+ stable, rapidly growing) | Kubernetes SIG project (battle-tested since 2016) |
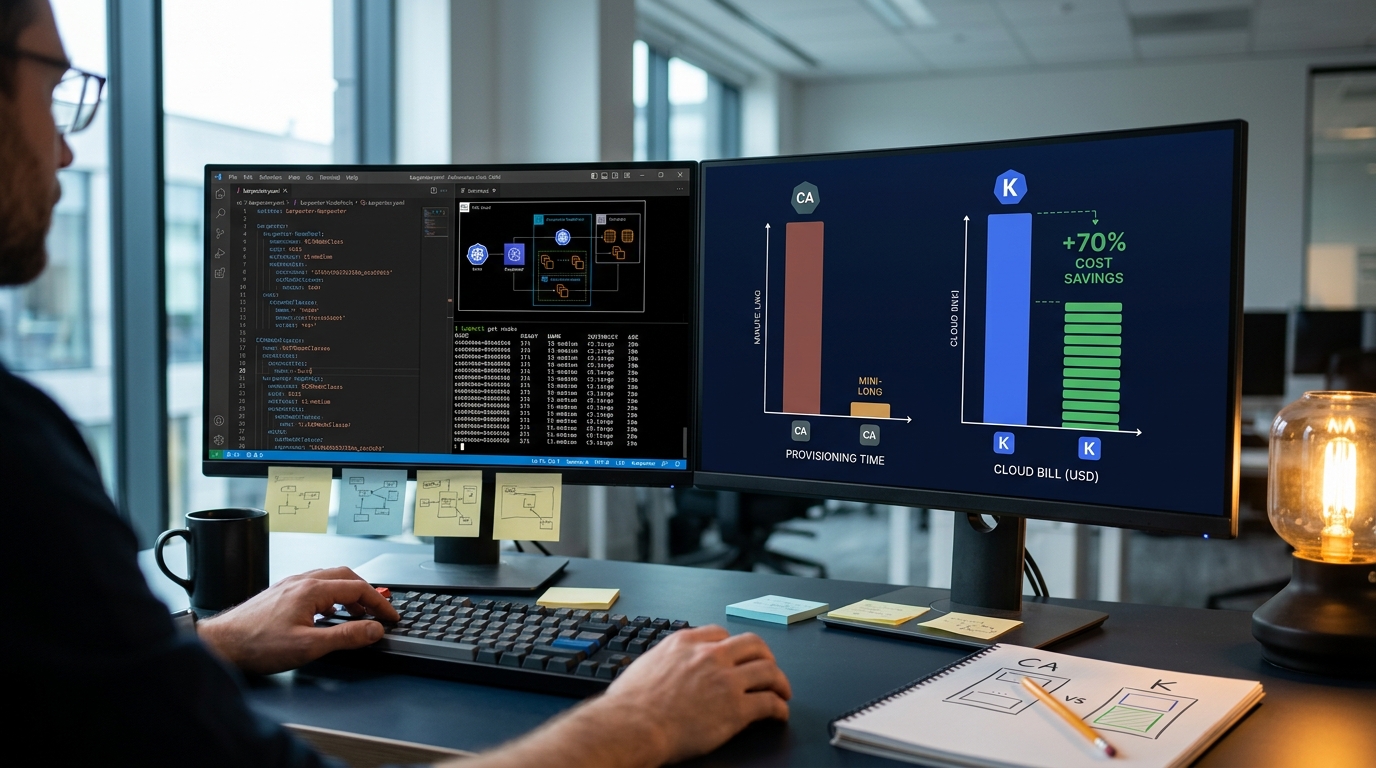
Deep-Dive Performance and Cost Benchmarks
When comparing cluster autoscaler vs karpenter performance, the numbers speak for themselves. Let's look at real-world benchmarks and a detailed case study illustrating how these architectural differences impact both speed and cloud spend.
Provisioning Speed Breakdown
In a standard AWS EKS setup, the time elapsed from a pod entering the Pending state to the pod reaching a Running status on a newly provisioned node breaks down as follows:
Cluster Autoscaler Timeline (Total: ~330s) [Pending] ──(10s Poll)──> [Simulate] ──(30s API)──> [ASG Launch VM] ──(180s Boot)──> [Kubelet Ready] ──(110s Pull/Run)──> [Running]
Karpenter Timeline (Total: ~85s) [Pending] ──(1s Watch)──> [Direct API Call] ──(5s)──> [EC2 Launch VM] ──(50s Boot)──> [Kubelet Ready] ──(29s Pull/Run)──> [Running]
- Pod Pending Detection: CA relies on a polling loop (default 10s, but often tuned higher in large clusters to prevent API rate limiting). Karpenter uses an event-driven model that watches the API server, responding in milliseconds.
- Decision Latency: CA must simulate scheduling against every configured node group. If you have 20+ node groups to support spot diversification, this simulation becomes extremely slow. Karpenter batches pending pods over a 10-second window, makes a single multi-dimensional bin-packing decision, and fires a direct API call.
- Instance Launch: CA modifies the ASG desired capacity. The ASG controller must reconcile this change, which introduces cloud-provider queue latency. Karpenter calls the EC2
RunInstancesAPI directly, bypassing the ASG controller entirely.
Real-World Case Study: B2B SaaS Platform Cost Reduction
A mid-sized B2B SaaS company running a multi-tenant platform on AWS EKS faced runaway cloud bills. Their cluster averaged 120 nodes managed by Cluster Autoscaler across 8 distinct managed node groups.
- The Problem: The company’s average cluster CPU/memory utilization sat at a miserable 34%. Because tenants onboarded dynamically, the team had to over-provision large instances to ensure fast setup times. This resulted in an average monthly EC2 compute bill of $127,000.
- The Solution: Working with DevOps consultants, they migrated the cluster entirely to Karpenter. They replaced their 8 static node groups with 2 dynamic NodePools (one general-purpose, one GPU-accelerated for AI workloads). They enabled
WhenEmptyOrUnderutilizedconsolidation with a 5-minute grace period and configured a Spot-first strategy for non-critical workloads. - The Results: Within 90 days, the platform's average cluster utilization jumped from 34% to 78%. Karpenter dynamically consolidated underutilized nodes and automatically packed workloads onto a highly diverse mix of 23 different instance types. The monthly compute bill plummeted to $35,500—a staggering 72% cost reduction with zero degradation in application performance.
Multi-Cloud Realities: AWS, Azure, and Karpenter GCP 2026
Historically, Karpenter was criticized as an AWS-only solution. However, since its donation to the CNCF, the community has made significant strides in decoupling Karpenter’s core scheduling logic from cloud-specific APIs. In 2026, the multi-cloud landscape looks highly dynamic, though important differences remain.
AWS (The Reference Implementation)
AWS remains the primary home and most mature environment for Karpenter. Features like native Spot instance interruption handling, AWS Fault Injection Service integration, and deep EC2 fleet allocation strategies are highly optimized. If you are running on EKS, Karpenter is the default recommended autoscaler.
Azure (Production-Stable)
Microsoft’s Karpenter provider (karpenter-provider-azure) has reached production-stable status. Azure integrates Karpenter concepts directly into AKS under the name Node Auto Provisioning (NAP). It allows Azure operators to bypass Virtual Machine Scale Sets (VMSS) and provision individual VMs directly, matching the speed and cost benefits seen on AWS.
Google Cloud Platform: Karpenter GCP 2026
For teams running on Google Cloud, the story is slightly different. The karpenter gcp 2026 provider is currently in Beta (karpenter-provider-gcp). While it is rapidly gaining features, many GCP-native teams prefer Google's proprietary scaling solutions.
Google Cloud’s GKE features GKE Autopilot and GKE Node Auto-Provisioning (NAP). GKE's native NAP is highly sophisticated, performing automatic node creation, sizing, and bin-packing directly within GKE's control plane.
For multi-cloud organizations, the choice between Karpenter and native tools comes down to architectural consistency:
Multi-Cloud Strategy Decision: Are you prioritizing a single, unified tool across all clouds? ├── Yes ──> Use Cluster Autoscaler (highly mature across AWS/GCP/Azure/DO) └── No ──> Use the best tool for each cloud: ├── AWS ──> Karpenter ├── Azure ──> Karpenter (AKS NAP) └── GCP ──> GKE Node Auto-Provisioning (NAP)
On-Premises Kubernetes: Is Autoscaling Ever Worth It?
As DevOps engineers explore cloud-like efficiencies on-premise, a common question arises in Reddit communities and platform engineering circles: Does Karpenter or any other node autoscaler make sense when running Kubernetes on-premise (e.g., via VMware vSphere, Proxmox, or bare metal)?
The Short Answer: No
Currently, Karpenter does not support on-premise environments. There are no official providers for vSphere, Proxmox, or bare metal. Karpenter's core architecture is built around calling dynamic cloud APIs with infinite capacity pools.
More fundamentally, from a financial perspective, autoscaling on-premises is a radically different equation than in the public cloud:
"If you're not capacity constrained and you've already paid for the hardware, then you don't gain any efficiency from autoscaling. It requires more engineering overhead and usually causes at least a few outages before you get it right. The most expensive asset is your engineering time; a well-planned, peak-provisioned infrastructure on-premise is incredibly stable." — Senior DevOps Engineer, r/kubernetes
When Does On-Prem Autoscaling Make Sense?
While scaling nodes up and down hourly on-premise is generally a waste of engineering effort, there are two specific scenarios where dynamic node management is valuable:
- Multi-Cluster Hardware Sharing: If you have a massive physical virtualization pool (e.g., 500 physical ESXi hosts) and multiple independent Kubernetes clusters (Dev, Test, Prod), you can use the Cluster Autoscaler with Cluster API (CAPI). This allows the Dev cluster to release virtual machines back to the shared hypervisor pool during off-hours so the Prod or Batch Processing cluster can utilize those physical resources.
- Automated Lifecycle Management: Even if you do not want to scale for cost, using an autoscaling mechanism is highly useful for node upgrades and drift management. Instead of manually draining, deleting, and recreating VMs when a new OS patch or Kubernetes version is released, you can let an autoscaler detect the "drift" and roll the nodes automatically, keeping your infrastructure clean and secure.
Step-by-Step Karpenter AWS Tutorial and Migration Path
If you have decided to transition from Cluster Autoscaler to Karpenter on AWS, this hands-on karpenter aws tutorial will guide you through a safe, zero-downtime migration path.
Step 1: Configure IAM Roles for Service Accounts (IRSA)
Karpenter requires permissions to launch, terminate, and describe EC2 instances. We will use AWS CLI and eksctl to set up the necessary IAM roles.
bash
Create the IAM Policy for Karpenter Controller
aws iam create-policy \ --policy-name KarpenterControllerPolicy-MyCluster \ --policy-document file://karpenter-policy.json
Create the IAM Role and associate it with the Karpenter ServiceAccount
eksctl create iamserviceaccount \ --cluster=my-cluster \ --namespace=kube-system \ --name=karpenter \ --role-name=KarpenterControllerRole-MyCluster \ --attach-policy-arn=arn:aws:iam::112233445566:policy/KarpenterControllerPolicy-MyCluster \ --approve \ --override-existing-serviceaccounts
Step 2: Install Karpenter via Helm
Deploy Karpenter to your EKS cluster using the official Helm chart. Ensure you target the Karpenter v1 release.
bash helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter \ --version 1.0.1 \ --namespace kube-system \ --set serviceAccount.create=false \ --set serviceAccount.name=karpenter \ --set settings.clusterName=my-cluster \ --set settings.interruptionQueue=my-cluster-queue \ --wait
Step 3: Apply Karpenter CRDs (NodePool and EC2NodeClass)
Apply the YAML manifests we defined in Section 3. This establishes your default NodePool and points it to your VPC subnets and security groups.
bash kubectl apply -f karpenter-ec2nodeclass.yaml kubectl apply -f karpenter-nodepool.yaml
Step 4: Implement a 4-Phase Migration Strategy
To migrate safely without risking production outages, execute the transition in four structured phases:
Phase 1: Deploy Karpenter alongside CA ──> Phase 2: Shift Non-Critical Workloads (Dev/Staging) │ Phase 4: Uninstall CA & Clean up ASGs <── Phase 3: Shift Production & Scale CA Node Groups to 0
- Phase 1: Coexistence. Run both Karpenter and Cluster Autoscaler in parallel. Add a taint to your Karpenter-managed nodes so that only workloads specifically configured with matching tolerations can schedule on them.
- Phase 2: Staged Workload Shift. Update your development and staging workloads to prefer Karpenter nodes. You can achieve this using node affinities:
yaml spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: karpenter.sh/initialized operator: Exists
- Phase 3: Production Shift. Once staging is stable, remove the CA node group affinities from your production workloads. Allow Karpenter to scale up new, optimized instances. Gradually scale down your CA-managed Auto Scaling Groups' minimum and desired capacities to
0. - Phase 4: Decommissioning. Once all workloads have run stably on Karpenter nodes for at least one week, uninstall the Cluster Autoscaler deployment from your cluster and delete the unused AWS ASGs and launch templates.
Kubernetes Node Autoscaling Best Practices
To achieve maximum efficiency and prevent common scaling failures, implement these k8s node autoscaling best practices in your production clusters.
1. Tune Kubelet Resource Reservations to Slash Startup Times
Many platform engineers blame Karpenter or CA for slow node provisioning when the bottleneck is actually the kubelet's startup configuration. By default, when a new VM boots, the kubelet performs intensive resource evaluation loops before marking the node as Ready.
As discovered by platform teams troubleshooting startup delays, you can cut node provisioning times in half by tuning your custom AMI's kubelet configuration:
- Set Explicit Reservations: Define
kube-reservedandsystem-reservedvalues based on actual historical system process usage. This stops the kubelet from guessing system overhead on startup. - Relax Eviction Thresholds: Aggressive default eviction thresholds can cause the kubelet to delay readiness reporting while trying to reclaim memory during noisy bootstrap phases. Relaxing
memory.availablefrom a hard100Mito200Miwith a soft threshold and a 90-second grace period stabilizes startup behavior. - Increase Update Frequency: Drop
node-status-update-frequencyfrom the default10sto4sso the control plane registers the node'sReadytransition significantly faster.
{ "kubeReserved": { "cpu": "100m", "memory": "300Mi" }, "systemReserved": { "cpu": "80m", "memory": "200Mi" }, "evictionHard": { "memory.available": "200Mi" }, "evictionSoft": { "memory.available": "300Mi" }, "evictionSoftGracePeriod": { "memory.available": "90s" }, "nodeStatusUpdateFrequency": "4s" }
2. Configure Robust PodDisruptionBudgets (PDBs)
Because Karpenter continuously consolidates underutilized nodes, pods will be evicted and rescheduled frequently. If your workloads do not have robust PodDisruptionBudgets defined, Karpenter's consolidation loops can cause brief application outages.
Always ensure your critical deployments define a PDB to guarantee high availability during consolidation events:
yaml apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: my-app-pdb namespace: production spec: minAvailable: 2 selector: matchLabels: app: my-app
3. Implement Over-Provisioning via "Pause" Pods
If your business requires sub-second scaling where you absolutely cannot wait 60 seconds for a node to boot, implement over-provisioning using low-priority "pause" pods.
Create a deployment running a lightweight pause container with a very low priority class. These pods will occupy space on your nodes. When a high-priority production pod needs to scale, the Kubernetes scheduler will instantly evict the pause pods to claim their resources, forcing the pause pods into a Pending state. The autoscaler will then provision a new node in the background for the evicted pause pods, ensuring your production workloads scale instantly without waiting for VM initialization.
Key Takeaways: The 2026 Decision Matrix
Choosing between karpenter vs cluster autoscaler in 2026 comes down to a few clear, practical parameters:
- Choose Karpenter if: You run primarily on AWS or Azure, manage clusters with more than 20 nodes, run highly dynamic or diverse workloads (batch processing, CI/CD, AI/ML), and want to maximize cost savings through automatic consolidation.
- Choose Cluster Autoscaler if: You run on GCP (and prefer not to use GKE NAP), DigitalOcean, or on-premises via Cluster API, require a single unified autoscaler across multiple different cloud providers, or have strict compliance requirements mandating traditional Auto Scaling Groups.
- Speed Advantage: Karpenter is significantly faster, scaling nodes in 60–90 seconds compared to Cluster Autoscaler's 5–10 minutes.
- Cost Advantage: Karpenter's dynamic bin-packing and continuous consolidation regularly deliver 30% to 70% cost savings over Cluster Autoscaler's basic scale-down heuristics.
Frequently Asked Questions
Is Karpenter a drop-in replacement for Cluster Autoscaler?
No. Karpenter uses a completely different architectural model. Instead of configuring Auto Scaling Groups, you configure declarative NodePool and EC2NodeClass CRDs. Migrating requires setting up the appropriate IAM roles, deploying Karpenter, and transitioning your workloads using node affinities and taints.
Can I run Karpenter and Cluster Autoscaler together?
Yes. Running both in parallel is the recommended migration strategy. You can restrict Karpenter to manage specific workloads (using taints and labels) while Cluster Autoscaler continues to manage your legacy node groups. Once you are comfortable with Karpenter, you can scale the CA node groups to zero and decommission it.
How does Karpenter handle Spot instance interruptions?
Karpenter has native, first-class support for Spot instances. It monitors AWS SQS queues for EC2 Spot Interruption Warnings, Rebalance Recommendations, and Instance State Change Notifications. When an interruption notice is received, Karpenter instantly pre-provisions a replacement node and gracefully drains the terminating node, completing the migration well within the 2-minute AWS warning window.
What happens if Karpenter itself goes down?
If the Karpenter controller crashes or goes down, your existing nodes and workloads will continue to run normally. However, no new nodes will be provisioned if pods go into a Pending state, and active consolidation or drift detection will pause. To mitigate this in production, deploy Karpenter with multiple replicas and enable leader election.
Does Karpenter support GPU and AI workloads?
Yes. Karpenter is highly optimized for AI/ML and GPU workloads. It natively understands GPU resource requests and can dynamically provision the exact GPU instance type (e.g., g4dn, g5, or p4d families) requested by your training or inference pods, eliminating the need to maintain expensive, idle GPU node pools.
Conclusion
As we navigate the complex landscape of cloud-native infrastructure in 2026, the choice of your Kubernetes node autoscaler is no longer just an operational detail—it is a critical driver of your engineering velocity and cloud budget efficiency. While Cluster Autoscaler remains a reliable, battle-tested tool for multi-cloud and on-premise environments, Karpenter’s groupless, event-driven architecture has set a new standard for performance and cost optimization on modern cloud platforms.
By cutting node provisioning times from minutes to under 90 seconds and dynamically consolidation underutilized resources, Karpenter empowers teams to run leaner, scale faster, and reclaim up to 70% of their compute spend.
Whether you decide to stick with the safety of Cluster Autoscaler or embrace the dynamic power of Karpenter, implementing the k8s node autoscaling best practices outlined in this guide—such as tuning your kubelets, establishing robust PDBs, and utilizing over-provisioning—will ensure your platform remains resilient, highly available, and ready for whatever traffic spikes come your way.


